

Kubernetes intro
Kubernetes today is the industry standard to host and run different kinds of container workloads. It’s really not possible nowadays to run containers without any orchestration or management tools.
Kubernetes itself consists of several components separated onto different groups: Control Plane (aka Master) and Worker (aka Nodes).
Control plane components
- etcd – key-value storage for cluster-related data.
- API Server is responsible for handling all REST communication and manages all Kinds available.
- Controller manager keeps the state actual (desired)
- Scheduler is the boss who decides what\when and how should be run inside the cluster. He manages k8s nodes and pods.
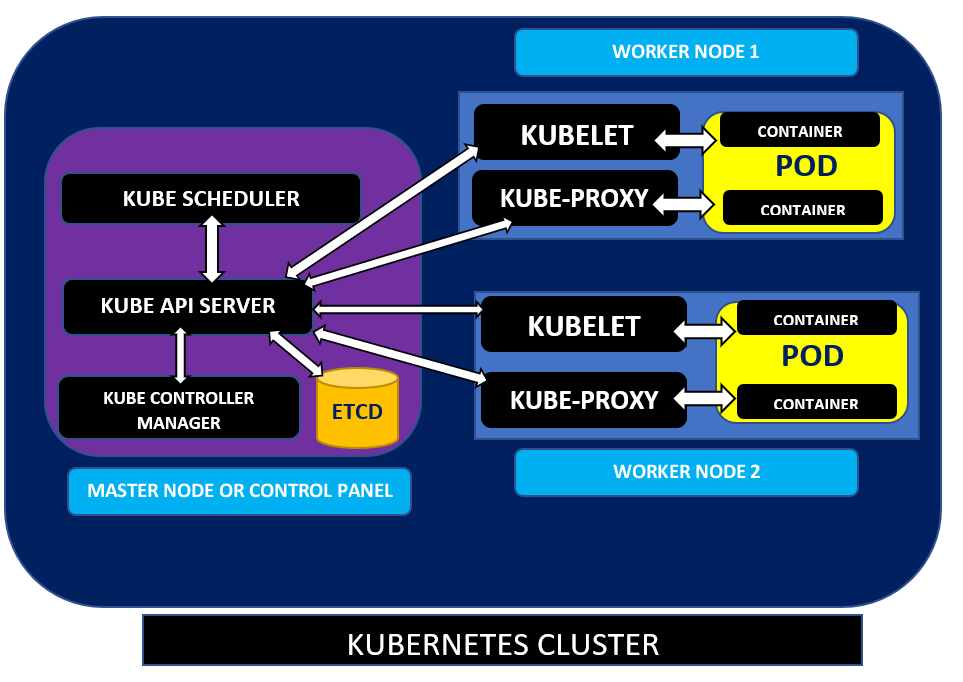
Nodes components:
- Kubelet – the “heart” of the node. It managed the interaction between node’s configuration, its runtime (Docker or ContainerD, CRI-O etc.)
- Kube-Proxy is responsible for traffic flow from\to K8S Control plane, containers and the external clients.
- Another important part of the k8s cluster (which is not a component of it technically) are Pods. It is the smallest deployable unit of computing that you can create and manage in Kubernetes.
Kubernetes scaling
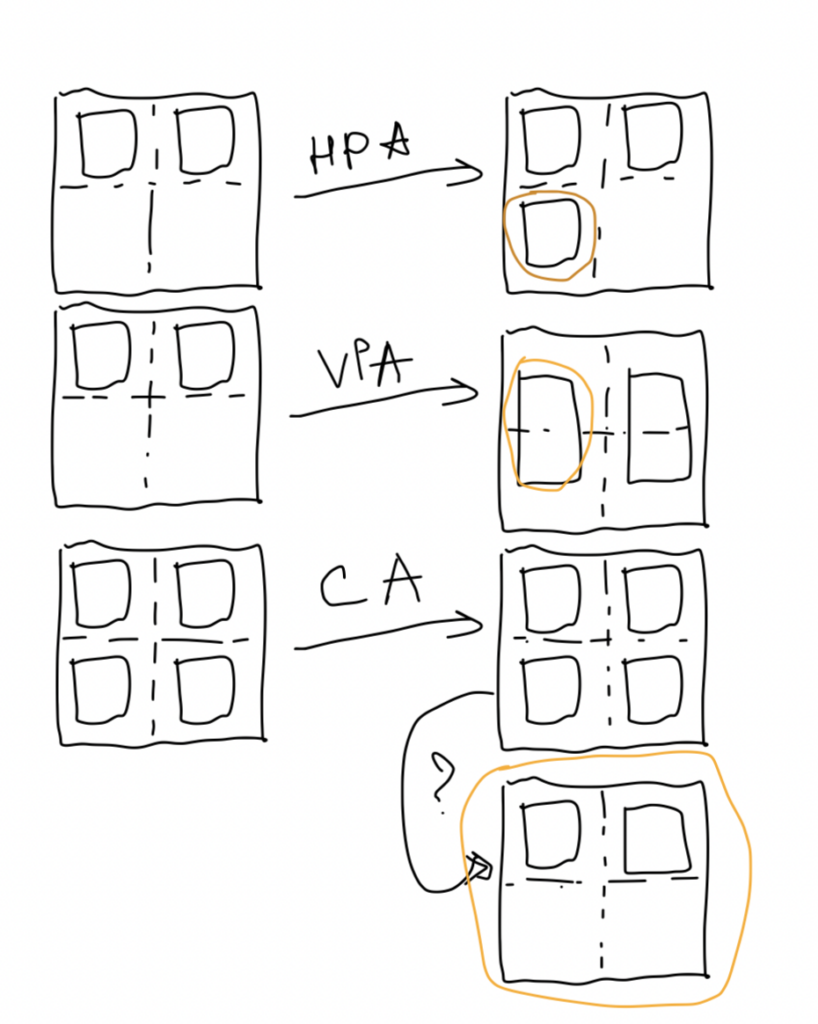
HPA (Horisontal Pods Auto-Scaling) – built-in feature allowing us to scale out pods based on some metrics and add more pods serving the same function.
VPA (Vertical Pods Auto-Scaling) – external operator (should be installed separately) allowing us to scale up our pods (give them more resources) based on some metrics or events.
CA (Cluster Auto-Scaler) – external operator allowing us to scale out our k8s nodes to handle more workloads (actively used together with HPA\VPA).
How does it work in real life?
- You deployed a pod with Nginx web server as a deployment (or just a replicaset). You have one worker node.
- Next you configured resources (requests and limits) constraints.
- It works pretty fine, but as soon as you receive a lot of requests – the limits can be reached (or you can experience some performance degradation) – it’s time for scaling.
- You can perform scale out action using
kubectl scale deploy/nginx --replicas=2command, but we want something automatic, right? - Then we configure the HPA which will use average CPU or (and) RAM utilisation metrics. And our life becomes better.
- But what will happen if the node cannot schedule a new pod which is created based on the HPA trigger? Nothing – it will stuck in “Pending” state.
- You can add one more worker node manually, but we want automation, so it’s time for Cluster Autoscaler – it will scale our worker nodes pool based on its configuration and the environment your cluster is running in. It will add one more node, and you’ll be happy.
Amazon Elastic Kubernetes service (EKS) scaling
EKS supports different types of node groups.
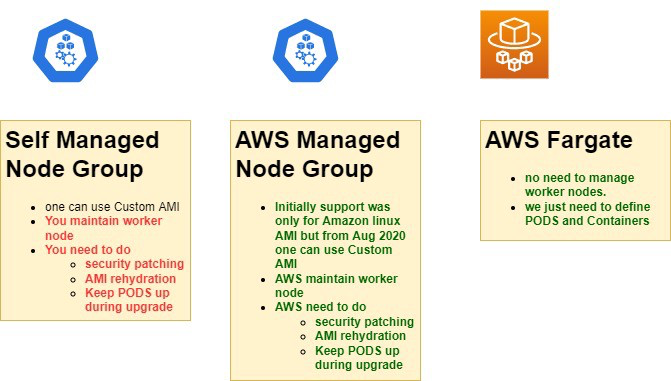
Typically we create self-managed and AWS manage node groups backed by the AWS Auto-Scaling group. You also can run the K8S node using just EC2 instance.
The cluster Auto-Scaler in the AWS uses auto-discovery of AWS Auto-Scaling groups based on the AWS tags to scale-out specific EKS Node pools if needed.
Meanwhile, the Karpenter just manages single EC2 instances based on some internal K8S API Object called “Provisioner”. This is really the base difference between them.
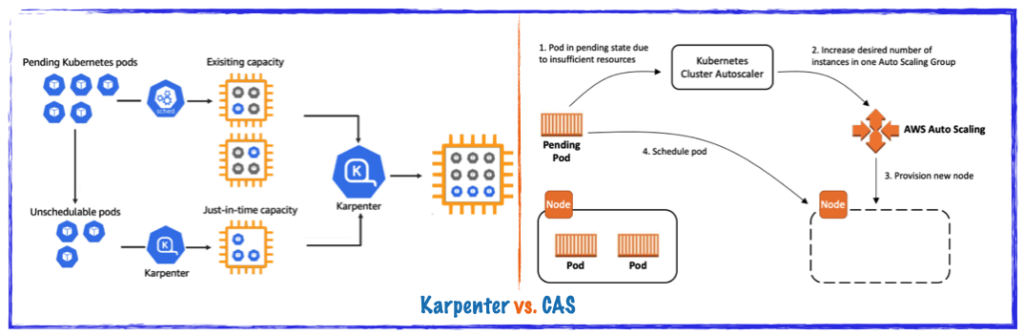
Demo: Cluster Auto-Scaler vs Karpenter
Let’s execute some demo to see how it works in reality.
We have some web K8S-based deployment (cpu consumptive) with some resources constraints configured together with defined HPA. We start with one worker node in the Cluster. This application is our privately developed small container which creates a CPU-load when we touch it on the /start path.
We will run performance load against our application:
> kubectl run load-generator --image=busybox -- /bin/sh -c "while true; do wget -q -O- http://demo.demo.svc.cluster.local/start; done"HPA will create more pods (up to 100) during some period of time. We will execute the same test for the Cluster Auto-scaler and the Karpenter.
Please, take into the consideration that we use the default HPA configuration, without any specific settings to test the CA and the Karpenter. We definitely can configure HPA to be more responsive and it’s highly recommended to do it for your production workloads.
Important note about HPA
Cluster-Autoscaler
Results:
- Around 6 minutes it took to handle load and add two more nodes
- 8 more minutes to handle spike with 40 additional pods – the CA added +11
t3a.largenodes - Finally It took ~30 minutes for the CA to return the initial state after the load stopped (mostly because of the 10 minutes TTL configured after the node become a “candidate to be removed”)
| Pros ( + ) | Cons ( – ) |
|---|---|
| Uses AWS AutoScaling groups | Uses AWS AutoScaling groups |
| Better reaction to some infrastructure interruptions | Consolidation works really weird sometimes |
| Has support for different cloud providers | Most of the time nodes are over-provisioned |
| Good customisation (for AWS ASGs) | Hard to manage different node groups (and instance types) – 1 node pool – 1 resources shape |
| More predictive | Spot instances and EBS\ASG conflicts |
Karpenter
Results:
- It took 5 minutes to handle load and add three more nodes
- It took 8 minutes to handle spike with 40 additional pods – the CA added several nodes (including really big one) to do it
- It took ~30 minutes for the Karpenter to return the initial state after the load stopped (mostly because of the 10 minutes TTL configured in the Provisioner to keep results close to each other)
| Pros ( + ) | Cons ( – ) |
|---|---|
| Does not use AWS ASG | Still relatively brand-new product |
| Really x5 (min) faster in real scenarios | AWS only |
| Provisioners give incredible flexability | Sometimes really hard to understand what does go wrong (logging) |
| The Karpenter can choose the best instance type for the workloads | Sometimes some strange things happen (see demo during the spike) with the EKS API |
| You can configure EBS disks, networking, security groups, AZ configuration etc for each pod\node you’re scheduling | Less predictive (especially without proper configuration and planning) |
Final thoughts and recommendations
As we’ve tested, the Karpenter shows really good scaling experience, has more settings and configurations. It gives us incredible flexibility to configure different nodes scaling settings to optimise overall platform reaction on load increase.
The CA meanwhile still gives us all features of the autoscaling groups in the AWS, allows to manage node pools. It also can be configured, but it typically applies to all existing node pools. Also the ASG “layer” slower because it depends on the AWS ASG reactions on some scaling events. Sometimes it really can be so “stupid” and “slow”.
The Karpenter really good at the node scaling in the AWS. Right now the AWS does really active development of it, so you need to be care of using it in the production systems.
Right now our recommendation is to mix tools, and run important (and plus-minus static workloads) using the CA together with the HPA.







